Bound form - In bound form an application component binds to the Service and allows Components and Service to interact with each other.
Started Free Form - Once started a service can run if free indefinitely or till the task completes depending or restart itself with a null or the same intent depending upon the use.
Creating the Service:
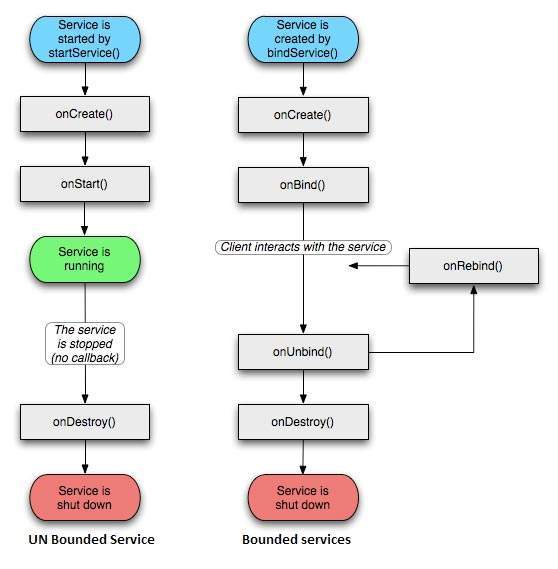
We can create a Service by extending the Service class of Android and overriding the callback methods. Also we need to declare the service in the Manifest file of the application. To have a clear idea of the running have a look at what might be the life cycle of a Service in Android in both bound and started form.
Bound Service and Communication:
There are three cases that we will discuss which are enumerated below:
1. When the Service and the Application both belong to the same process then by implementing a binder they can communicate by calling public methods of the Service [TODO]
2. Implementing a Messenger to handle IPC requests
3. Implementing AIDL to allow the operating system to pass the message between boundaries.
In this post we will handle only case one after which we will follow up on the other cases in the upcoming posts. In our example we call a Activity that fires up a service if it is not running which then which then fires up the activity based on a boolean value present in the activity.The code along with the explanation in comments is given below.
//MainActivity.java
package com.example.activityservicecommunication;
import com.example.activityservicecommunication.MyService.MyBinder;
import android.app.Activity;
import android.app.ActivityManager;
import android.app.ActivityManager.RunningServiceInfo;
import android.content.ComponentName;
import android.content.Context;
import android.content.Intent;
import android.content.ServiceConnection;
import android.os.Bundle;
import android.os.Handler;
import android.os.IBinder;
import android.util.Log;
import android.widget.Toast;
public class MainActivity extends Activity {
private final String serviceName = "com.example.activityservicecommunication.MyService";
private boolean isRanging = false;
MyService myservice; //stores the current instance of the Service
boolean isBound = false; //value to check if the current instance is present
/**
* This connection is given which assigns our service class with the instance of the
* running service when the activity binds to the service and sets the value of the bound
* variable as true.
*/
private ServiceConnection myConnection = new ServiceConnection(){
@Override
public void onServiceConnected(ComponentName name, IBinder service) {
MyBinder binder = (MyBinder) service;
myservice = binder.getService();
isBound = true;
}
@Override
public void onServiceDisconnected(ComponentName name) {
isBound = false;
}
};
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
if(isMonitoringServiceRunning()){
//donot fire up
Toast.makeText(getApplicationContext(), "Service already running", Toast.LENGTH_SHORT).show();
}else{
//fire up the service
Toast.makeText(getApplicationContext(), "Starting Service", Toast.LENGTH_SHORT).show();
Intent serviceIntent = new Intent(getApplicationContext(),MyService.class);
bindService(serviceIntent,myConnection,Context.BIND_AUTO_CREATE);
}
//simulate the changing values of the variables
new Handler().postDelayed(new Runnable(){
@Override
public void run() {
isRanging = true;
if(isBound){
Toast.makeText(getApplicationContext(), "You should get Notifcation now", Toast.LENGTH_SHORT).show();
myservice.setRanging();
}
new Handler().postDelayed(new Runnable(){
@Override
public void run() {
isRanging = false;
if(isBound){
Toast.makeText(getApplicationContext(), "You should get Notifcation now", Toast.LENGTH_SHORT).show();
myservice.unsetRanging();
}
}
}, 5000);
}
}, 5000);
}
@Override
protected void onStop() {
super.onStop();
if(isBound){
unbindService(myConnection);
isBound = false;
}
}
private boolean isMonitoringServiceRunning(){
ActivityManager manager = (ActivityManager)getSystemService(ACTIVITY_SERVICE);
for(RunningServiceInfo service:manager.getRunningServices(Integer.MAX_VALUE)){
Log.d("MESSAGE",service.service.getClassName());
if(serviceName.equals(service.service.getClassName())){
return true;
}
}
return false;
}
}
package com.example.activityservicecommunication;
import android.app.Notification;
import android.app.NotificationManager;
import android.app.PendingIntent;
import android.app.Service;
import android.content.Context;
import android.content.Intent;
import android.os.Binder;
import android.os.IBinder;
import android.widget.Toast;
public class MyService extends Service {
private final IBinder mbinder = new MyBinder();
private boolean isRanging = false;
private boolean prevValue = false;
private NotificationManager notificationManager;
private static final int NOTIFICATION_ID = 123;
public class MyBinder extends Binder{
MyService getService(){
return MyService.this;
}
}
@Override
public IBinder onBind(Intent intent) {
return mbinder;
}
@Override
public void onCreate() {
notificationManager = (NotificationManager) getSystemService(Context.NOTIFICATION_SERVICE);
new Thread(){
@Override
public void run() {
while(true){
if(isRanging!=prevValue){
postNotification("Rabging Value Changed");
prevValue = isRanging;
}
}
}
}.start();
super.onCreate();
}
public void setRanging(){
isRanging = true;
}
public void unsetRanging(){
isRanging = false;
}
private void postNotification(String msg) {
Intent notifyIntent = new Intent(MyService.this, MyService.class);
notifyIntent.setFlags(Intent.FLAG_ACTIVITY_SINGLE_TOP);
PendingIntent pendingIntent = PendingIntent.getActivities(
MyService.this,
0,
new Intent[]{notifyIntent},
PendingIntent.FLAG_UPDATE_CURRENT);
Notification notification = new Notification.Builder(MyService.this)
.setSmallIcon(R.drawable.beacon_gray)
.setContentTitle("Notify Demo")
.setContentText(msg)
.setAutoCancel(true)
.setContentIntent(pendingIntent)
.build();
notification.defaults |= Notification.DEFAULT_SOUND;
notification.defaults |= Notification.DEFAULT_LIGHTS;
notificationManager.notify(NOTIFICATION_ID, notification);
}
}
Put in some xml layout according to the code and register the service in the manifest. You should see two notifications coming up according to when the activity changes the isRanging value in the Service via the public methods.
